


Первая программа статистической обработки текста, с которой я столкнулась в Интернете - Wordstat (распространяется бесплатно).
Пользоваться программой предельно просто - выбираете файл (правда, поддерживаются только форматы txt и html\htm), нажимаете на кнопку и через секунду получаете файл - опять в формате txt - с ключевыми словами:
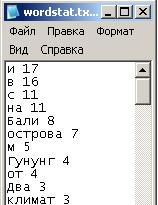
Как можно заметить по результатам, алгоритм программы также предельно прост: программа считает количество употреблений каждого слова, и на основании этих данных строит свой список-рейтинг. В результате - на первое место попадают предлоги, союзы, артикли - совсем не то, что в действительности несет важную информацию. К тому же, слова анализируются только "в розницу" - это минус, ведь в глоссарий ключевых терминов нужно включать и словосочетания.
Таким образом, я продолжила свой поиск и нашла программу TextAnalyst (распространяется бесплатно), обладающую более совершенным алгоритмом, учитывающую, наряду с частотностью, целый ряд лингвистических параметров: положение слова в предложении, положение предложения в тексте, связь слов между собой, семантические параметры.
И, хотя в результатах получается много "шума", важные термины действительно выделяются и могут быть использованы для создания глоссария ключевых слов. К сожалению, чудо-программка поддерживает только русский язык.
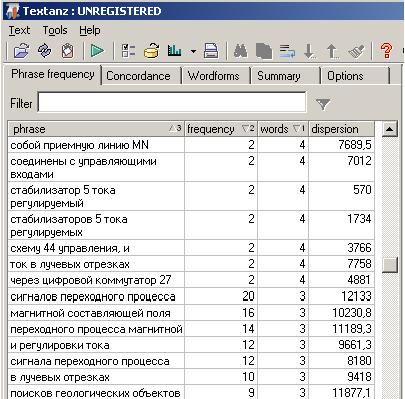
Если исходный текст - на английском языке (или другом языке, с письменностью кириллицей или латиницей), то можно воспользоваться моей следующей находкой - программой Textanz. По сравнению с отечественной программой TextAnalyst, программа Textanz использует более "грубые методы" и ограничивается только анализом частотности. Единственная лингвистическая премудрость этой программы - способность не учитывать предлоги, союзы и артикли и прочие слова, занесенные в специальный список. Очевидно, именно простота алгоритма и позволяет программе работать со многими языками.
Разумеется, если Вам необходимо создать профессиональный глоссарий текста большого объема, лучше воспользоваться специализированной программой. Упомянутые выше программы подойдут, скорее, для беглого изучения содержания текста перед переводом (чтобы лучше оценить тематику), выделения ключевых терминов и отслеживания их перевода "для себя".